Kaum ein Begriff sorgt selbst unter Data-und-Analytics-Experten für so viel Diskussion wie „Metadaten“ oder „Metadaten-Management“. Selbst eine scheinbar so simple Frage wie „Was sind Metadaten?“ bietet Raum für verschiedene Interpretationen und Zirkeldefinitionen. Ganz zu schweigen von der Beantwortung der Frage „Wie wichtig ist Metadaten-Management für ein Unternehmen?“. Dies gleicht schon fast einer Glaubensfrage. In diesem Blog-Beitrag wollen wir aber keine Glaubensfragen stellen oder beantworten, sondern uns stattdessen die Bedeutung von Metadaten für das Gelingen und die Optimierung von Data-und-Analytics-Projekte im Detail anschauen. Dabei beantworten wir auch die Fragen: Was sind Metadaten überhaupt? Warum ist die Unterscheidung zwischen technischen und fachlichen Metadaten so wichtig? Was sind die Vorteile, was der Nutzen von einem systematischen Metadaten-Management?
Definition: Was sind Metadaten?

Oft wird die Frage „Was sind Metadaten?“ mit der Phrase „Metadaten sind Daten über Daten“ beantwortet. Was mit Sicherheit nicht falsch ist, aber leider wenig dazu beiträgt, einem Laien das Konzept von Metadaten wirklich hinlänglich verständlich zu machen. (Da trifft es der Comic von geek & poke schon um einiges besser 😉)
Erweitert man diese Definition aber bereits ein wenig, wird das Wesen von Metadaten schon deutlich klarer: Metadaten oder auch Metainformationen sind strukturierte Daten, die Informationen über die Merkmale anderer Daten enthalten.
Metadaten dienen also dazu, die eigentlichen Daten näher zu beschreiben, um sie für den Betrachter verständlicher zu machen. Man könnte auch sagen, Metadaten betten die eigentlichen Daten in einen übergreifenden Kontext ein.
Schauen wir uns das mal an einem einfachen Beispiel an. In einem Customer-Relationship-Management-System (kurz: CRM) findet sich folgender Datensatz:
MAX MUSTERMANN, HEAD OF MUSTERABTEILUNG, MUSTERUNTERNEHMEN
Dieses Beispiel ist selbstredend natürlich sehr einfach und auch ohne mitgeführte Metadaten für nahezu jeden aus unserem Breitengrad eindeutig interpretierbar.
Werden die Metadaten jedoch mitgeführt, müsste sich aber definitiv niemand mehr hinsichtlich abweichender Interpretationen dieses Datensatzes Gedanken machen. Die Art und Weise wie diese Daten zu lesen und zu verstehen sind, wäre im Sinne des Erzeugers schwarz auf weiß festgelegt. Die Metadaten zu diesem Datensatz könnten folgendermaßen aussehen:
[VORNAME] [NACHNAME], [JOBBEZEICHNUNG], [UNTERNEHMENSNAME]
Erste Vorteile von Metadaten und Metadaten-Management
MAX [VORNAME] MUSTERMANN [NACHNAME], HEAD OF MUSTERABTEILUNG [JOBBEZEICHNUNG], MUSTERUNTERNEHMEN [UNTERNEHMENSNAMEN]
Ein so angereicherter Datensatz oder besser, viele angereicherte, baugleiche Datensätze bergen bereits einige Vorteile in sich:
1. Es lassen sich Filter auf Metaebene erzeugen.
Zum Beispiel: Zeige mir alle Datensätze an, deren [VORNAME]-Feld nicht leer ist, genau dem Ausdruck XY entsprechen, ungleich Ausdruck XY sind etc.
2. Es lassen kombinierte Abfragen durchführen.
Zum Beispiel: Zeige mir alle Datensätze an, deren [VORNAME]-Feld leer ist, aber deren [NACHNAME]-Feld nicht leer ist etc.
3. Es lässt sich gezielter, transparent und fehlerfrei mit anderen über Datensätze sprechen und Anweisungen geben.
Zum Beispiel: Bitte erstelle mir eine Liste aller Kontakte deren [VORNAME]-Feld genau MAX enthält etc.
4. Es lässt sich die tatsächliche Qualität von Datensätzen besser überprüfen und optimieren.
Zum Beispiel: Zeige mir alle Datensätze an, deren [VORNAME]-Feld eines von diesen Zeichen enthält !"§$%&/()=? etc.
Zusammenfassend lässt sich sagen, Metadaten ermöglichen nachgelagerte Datenanalysen auf einem deutlich besseren Niveau – als ohne selbige.
Welche Bedeutung haben Metadaten für die Arbeit mit Daten?
Die Verwaltung von Metadaten ist wahrscheinlich eine der kritischsten Aufgaben, die mit einem erfolgreichen Data-und-Analytics-Programm verbunden ist. Und zwar aus folgenden Gründen:
- Metadaten kapseln die konzeptuellen, logischen und physischen Informationen, die erforderlich sind, um ungleichartige Datensätze in einen zusammenhängenden Satz von Modellen für die Analyse umzuwandeln.
- Metadaten erfassen die Struktur der Daten, die für den Aufbau eines Data Warehouses oder allgemein für die Vorbereitung von weiterführenden Datenanalysen (Advanced Analytics) oder ein Berichtswesen (CPM- und BI-Reporting) notwendig sind.
- Die Aufzeichnung operativer Metadaten bietet einen Fahrplan für die Ableitung eines Informationsaudit-Trails – also der Überwachung von Änderungs- und Löschungshandlungen der unterschiedlichen Data Workers in einem Unternehmen. Datenmanipulationen und auch geänderte Business Rules lassen sich so über einen großen Zeitraum nachverfolgen.
- Metadaten-Verwaltungsprozesse bieten eine optimale Grundlage und Möglichkeit, die verschiedenen Bedeutungen, die mit den Quelldaten verbunden sind, zu trennen. Zudem helfen sie nach Veröffentlichung der Daten, beispielsweise in Berichten und Analysen, Abhängigkeiten, Herkunft und Qualität selbiger transparent zu halten.
- Mithilfe von Metadaten lässt sich zudem die Evolution von Informationen nachverfolgen – also aus welchen Datenquellen sich Informationen speisen, zusammensetzen oder generieren. Das hilft um Analyseergebnisse zu validieren und zu verifizieren.
Unterschied zwischen technischen und fachlichen Metadaten
Die Metadaten zum Datensatz
MAX MUSTERMANN, HEAD OF MUSTERABTEILUNG, MUSTERUNTERNEHMEN
könnten aber auch so aussehen:
[FIRSTNAME] [LASTNAME], [JOBTITLE], [COMPANY]
Blöderweise kommen beide Metadaten-Sätze aus demselben CRM-System. Blöderweise? Weil damit die Eindeutigkeit der Metadaten ein stückweit verloren geht. Welche Metadaten sind also führend? Bevor wir uns dieser Frage widmen, jedoch zunächst die Frage: Woher kommt eigentlich dieser neue Metadatensatz?
Hierbei handelt es sich um die sogenannten technischen Metadaten. Also um die Metadaten, die automatisch durch die dem CRM-zugrundeliegende Datenbank automatisch vergeben werden und sich nicht so ohne weiteres mehr ändern lassen, weil hieran mitunter die Systemlogik und Funktionsweise der Datenbank verknüpft ist.
Wir haben es also in aller Regel mit zwei unterschiedlichen Arten von Metadaten zu tun: den fachlichen und den technischen Metadaten.
Fachliche Metadaten
[VORNAME] [NACHNAME], [JOBBEZEICHNUNG], [UNTERNEHMENSNAME]
Technische Metadaten
[FIRSTNAME] [LASTNAME], [JOBTITLE], [COMPANY]
Definition: Fachliche Metadaten
Die fachlichen Metadaten erfüllen den Zweck, dass sie in der Regel sprechender gegenüber dem Anwender sind und somit deutlich besser verständlich. Fachliche Metadaten sollten deshalb auch durch die Fachanwender vergeben werden und der Verarbeitbarkeit im Sinne der Geschäftslogik entsprechen.
Fachliche Metadaten umfassen beispielsweise Fachbegriffe, domänenspezifisches Wissen oder Kontextinformationen wie benutzte Maßeinheiten oder Datumsformate. Sie dienen dem Endanwender, damit er die Analyseanwendungen effektiver einsetzen, relevante Daten finden und Auswertungen interpretieren kann.
Definition: Technische Metadaten
Die technischen Metadaten erfüllen den Zweck der Aufrechterhaltung der Funktionsweise des Systems und sind in aller Regel nicht oder nur aufwändig änderbar. In jedem Fall sind sie nicht durch den Fachanwender änderbar und weichen von den fachlichen Metadaten ab.
Technische Metadaten umfassen zum Beispiel Beschreibungen der Datenschemata oder Transformation und Analyse der Daten wie den Dateiname, das Erstellungsdatum, die Beschreibung oder den Autor. Sie sind von Administratoren und Anwendungsentwicklern erstellt worden und sind für sie bestimmt. Metadaten können aktiv (wenn sie zum Ausführungszeitpunkt von entsprechenden Werkzeugen interpretiert und ausgeführt werden), passiv (als konsistente Dokumentation), oder semiaktiv (bei Speicherung von Strukturinformationen) genutzt werden.
Man könnte meinen, in einer perfekten Welt wären die fachlichen und technischen Metadaten deckungsgleich. Zum einen ist die Welt aber schlicht nicht perfekt, zum anderen haben beide Arten der Metadaten ihre Berechtigung und verfolgen unterschiedliche Ziele, weshalb eine Abweichung in vielen Fällen Sinn macht.
Jedoch sollten beide Metadatenarten direkt miteinander in Beziehung gesetzt werden, um Reibungsverluste zwischen Fachanwender und IT-Abteilung zu verhindern. Das bekannte Thema Business-IT-Alignment führt uns dann auch auf geradem Wege zum Thema Metadaten-Management.
Darum ist Metadaten-Management wichtig
Ein System für sich genommen bringt also bereits schon zwei Arten von Metadaten mit sich: technische und fachliche. Und zwei Ausprägungsformen. Zwei Systeme bringen zwar immer nur noch zwei Arten von Metadaten mit sich, aber schon vier Ausprägungsformen. Drei bereits sechs und so weiter und so fort. Erschwerend kommt hinzu, dass mit aller Wahrscheinlichkeit nach der Datensatz
MAX MUSTERMANN, HEAD OF MUSTERABTEILUNG, MUSTERUNTERNEHMEN
sich so oder so ähnlich nicht nur im CRM-System wiederfindet, sondern auch im ERP-System …
Ein Analyse-System das sowohl das CRM- als auch das ERP-System anzapft, hat es also zum einen mit Duplicate Content zu tun und zum anderen mit abweichenden Metadaten mal zwei. Das richtige Referenzieren bzw. das Anreichen der Datensätze mit Informationen aus beiden Systemen ist aber essentiell für die Qualität des Analyseergebnisses.
Leider sind auch die Daten und ihre Metadaten nicht immer so sprechend wie in dem gewählten Beispiel. Oftmals ist der tatsächliche Kundenname nämlich nicht sofort aus dem Quellsystem ersichtlich, sondern ist an sich bereits verschlüsselt. So verbergen sich je nach System die Klarnamen der Kundenunternehmen hinter einer Customer-ID mit der Sie wenig bis gar nichts unmittelbar anfangen können.
Jeder, der sich mit Daten in einem Unternehmen beschäftigt, kennt wahrscheinlich die Frage: Wo befinden sich meine Bestellungen? Wenn Sie sich mit dieser Frage an Ihre IT-Abteilung wenden, dann bekommen Sie wahrscheinlich eine Antwort, wie: Die befinden sich in einer Tabelle mit dem Namen SalesOrderHeader. Wenn Sie sich dann die Tabelle anschauen, stellen Sie fest, dass die gewünschten Informationen schon irgendwie da sind, aber wahrscheinlich eher nicht in der Form, die Sie wirklich brauchen würden, um sofort weiterarbeiten zu können. Denn so finden sich in der Tabelle keine sprechenden Daten, sondern in sich wieder verweisende Daten, wie zum Beispiel eben die Customer-ID, oder die Sales-Person-ID, die Territory-ID etc. (Abbildung 1) Wenn Sie nun also wissen wollen, welcher Kunde sich hinter einer bestimmten Customer-ID verbirgt, dann müssen Sie nun an Ihre IT zurückfragen, wo finde ich denn weiterführende Informationen zu einer speziellen Customer-ID?

Abbildung 1: Zum Vergrößern bitte klicken
Daraufhin bekommen Sie eine neue Datenbanktabelle zurück, in der Sie nach der Customer-ID filtern können und zusätzliche Kundeninformationen enthalten sind. Den Klarnamen suchen Sie hier aber nach wie vor vergeblich. Was an diesem kleinen Beispiel klarwerden sollte, es gibt unterschiedliche Erkenntnisinteressen und die Frage nach den Kundendaten kann unterschiedliche Ausprägungen haben, die alle für sich genommen nicht falsch sind, aber zu deutlichen Reibungsverlusten in der Kommunikation rund um Daten führen.
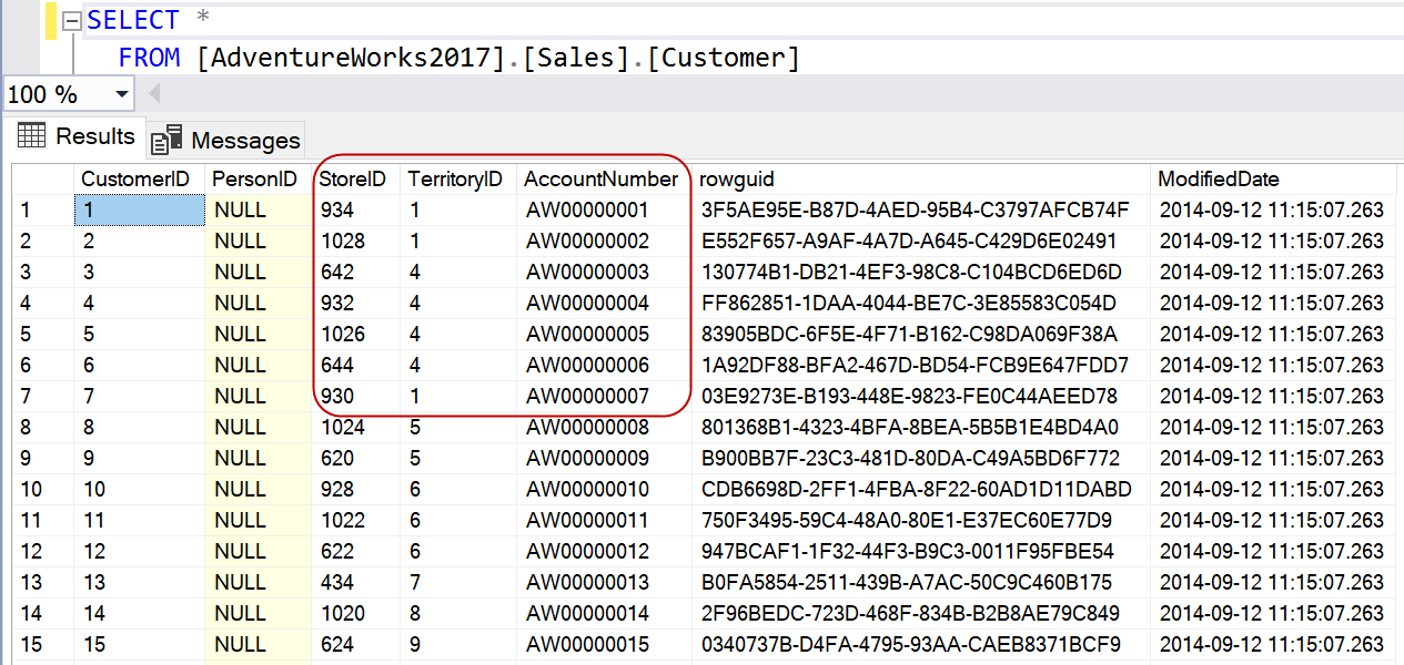
Abbildung 2: Zum Vergrößern bitte klicken
Ein Service muss also her, der verschiedene Daten-Assets in einem zentralen Metadatenverzeichnis verwaltet und zugänglich macht. Je nach System heißen solche Services Data Dictionary, ER-Diagramm oder Data Catalog.
Diese Services sind überhaupt erst die notwendig Grundlage, um Daten auswerten zu können bzw. überhaupt erst verstehen zu können.
Beispiel SAP Data Dictionary

Auszug SAP Dictionary: Zum Vergrößern bitte klicken
Hier findet man die Beschreibungen zu den einzelnen Tabellen, zu den Feldern in den Tabellen und auch zu den Beziehungen der Tabellen untereinander.
Beispiel SQL Server Information Schema
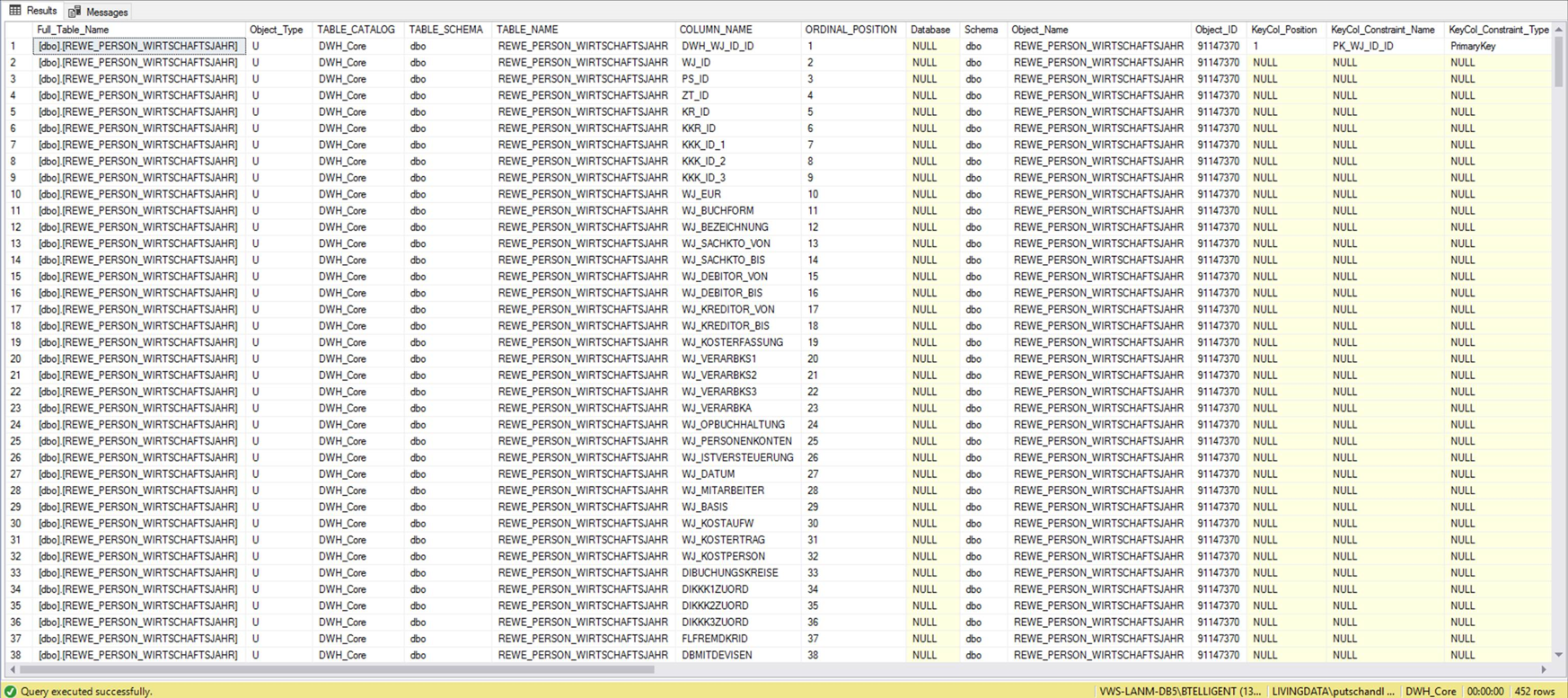
Auszug SQL Server Information Schema: Zum Vergrößern bitte klicken
Auch hier werden alle Tabellen, alle Felder, Key-Felder, Datentypen etc. beschrieben.
Leider sind auch die beiden vorangegangenen Beispiele nicht so leicht lesbar, da sie fast ausschließlich in Tabellenform daherkommen.
Deshalb gibt es auch andere Darstellungsformen.
Beispiel ER-Diagramm, oder auch: Entity-Relationship-Diagramm
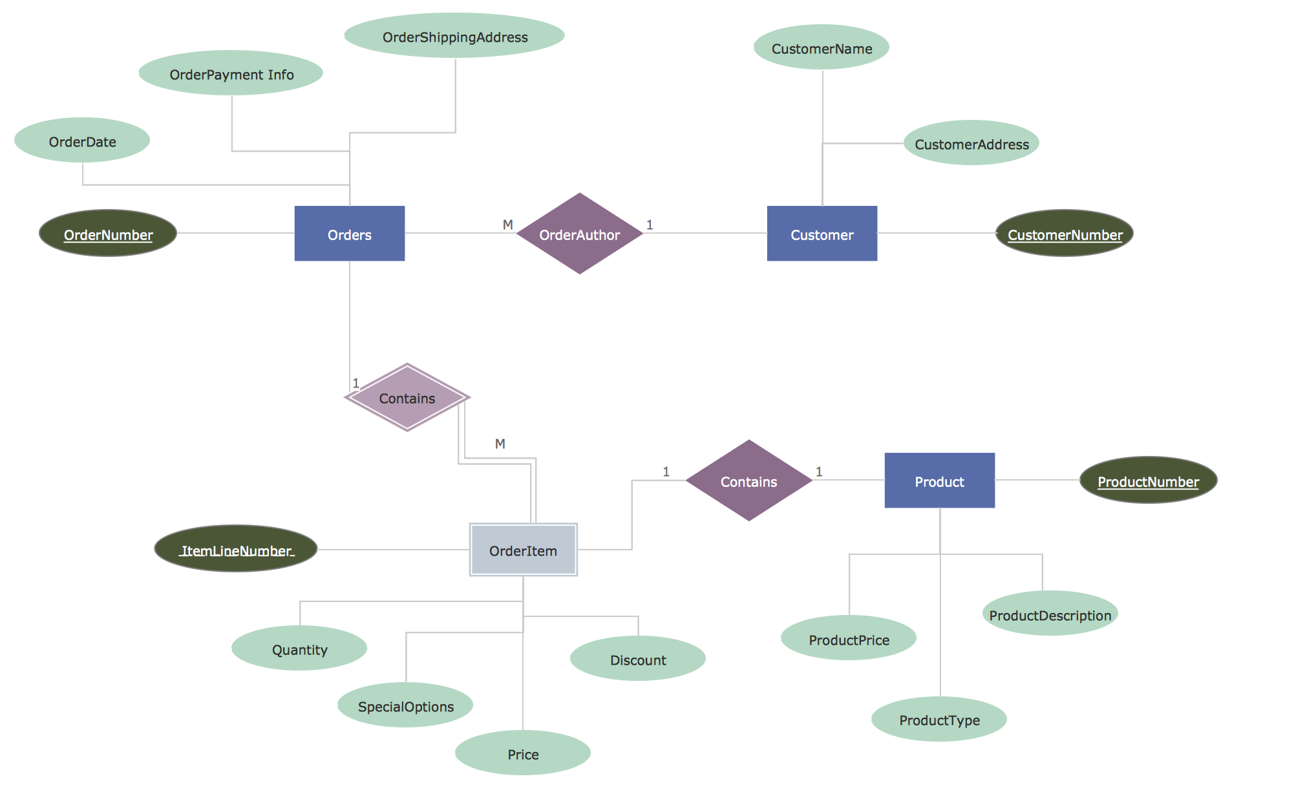
Auszug ER-Diagramm: Zum Vergrößern bitte klicken
Hier werden die unterschiedlichen Daten-Entitäten grafisch aufbereitet und deren Beziehungen zueinander schon deutlich besser dargestellt.
Sie sehen also, die Möglichkeiten sich um das Management seiner Metadaten zu kümmern, kann durchaus vielfältig sein. In den letzten Jahren hat sich das Bewusstsein dorthin gehen bereits erweitert und mittlerweile finden sich in Unternehmen zum Teil auch große Data Catalogs zum Management der Metadaten vor.
Beispiel Data Catalog
Auszug Data Catalog: Zum vergrößern bitte klicken
Die gezeigten Beispiele sind auf jeden Fall schon mal Schritte in die richtige Richtung und werden zum Teil auch durch integrierte Services in den Systemen mitgeliefert. Sie reichen aber nicht aus!
Denn diese Services beziehen sich ausschließlich auf die technischen Metadaten. Aber die rein technische Implementierung der Daten, ohne fachliche Zusammenhänge zum eigentlichen Business erzeugt kein Datenverständnis im Sinne der Fachanwender.
Vielmehr ist es notwendig, die technische Darstellung der Daten um die fachliche, geschäftsrelevante Darstellung der Daten zu ergänzen. Die technische Datenbankbeschreibung verliert den Bezug zu den eigentlichen fachlichen Inhalten.
Besonders dramatisch wird dieses Umstand, wenn man es mit „customized“ Systemen zu tun hat, die vom Standard abweichen. Denn hier werden Dateninhalte häufig für spezielle und kundenspezifische Zwecke entfremdet, so dass der Gap zwischen den technischen Metadaten und der eigentlich fachlichen Verwendung immer größer wird. Ohne eine entsprechende Dokumentation ist die Gefahr groß, dass die Systeme spätestens bei Knowhow-Verlust durch den Weggang von Mitarbeitern nicht mehr wartbar werden.
Daher ist es wichtig, dass die technischen Metadaten um die entsprechenden fachlichen Metadaten ergänzt werden. Also das Wissen der IT mit dem Wissen aus den jeweiligen Fachbereichen verbunden wird. Durch die Ergänzung der technischen Metadaten um die fachliche Komponente sprechen wir auch nicht mehr von Data Governance, was seinen Ursprung in der technischen Darstellung hat, sondern von Data Excellence. Also dem Wissensmanagement rund um Daten.
Dieses Wissensmanagement geht auch über die reine Datensicht hinaus. So werden dort auch Metadaten zu Berichtsobjekten, Kennzahlen, KPIs, weiteren Berechnungen etc. gesammelt und gepflegt, die die nachgelagerte Analysearbeit weiter vereinfacht.
Modernes Metadatenmanagement, zeichnet sich also dadurch aus, dass ...
- die technischen mit den fachlichen Metadaten "gematched" und in Beziehung zueinander gesetzt werden.
- es einen zentralen Service gibt, der systemübergreifend die technischen und dazugehörigen fachlichen Daten zur Analyse bereitstellt und
- nicht nur die Datenobjekte als solches beschreibt, sondern auch daraus abgeleitete Kennzahlen, KPIs, Berichte, Dashboards etc. erfasst und entsprechend beschreibt.
Zusammenfassung: Was ist Data Excellence?
Data Excellence ist mehr als reines technisches Data Governance. Nämlich, Data Excellence wird um die fachliche Sicht der Dinge angereichert. Ohne den technischen Konnex zu verlieren. Dadurch erreichen Sie einen exzellenten Umgang mit Daten. Sie beherrschen Ihre Daten also nicht mehr nur rein technisch, sondern eben auch fachlich. Sie verstehen also Ihre Daten besser und Sie vertrauen Ihren Daten deshalb auch deutlich mehr. Gleichzeitig minimieren Sie auch durch modernes Metadatenmanagement den Aufwand, den Sie in die Aufbereitung und Pflege Ihrer Data Assets stecken müssen. Wichtig dabei ist, dass Sie verstehen, dass die Einführung von Data Excellence nicht ausschließlich eine Sache der IT-Abteilungen ist, sondern es bedarf eines fundierten fachlichen Rahmens, in dem die Daten verstanden und verwendet werden können. Die IT stellt die Grundlage zur Verfügung, aber nicht das Datenverständnis. So gesehen ist Data Excellence die Basis für die Herausforderungen der Digitalisierung, von Big-Data-Initiativen und datengetriebenen Innovationsprozessen.
Weitere Beiträge
Die Bedeutung von Data Governance für den Schutz sensibler Daten
In der heutigen digitalen Ära ist der Schutz sensibler Daten von entscheidender Bedeutung. Unternehmen und Organisationen stehen vor der...
Wie eine starke Datenstrategie Ihr Unternehmen vorantreibt
Die Fähigkeit, aus Daten wertvolle Erkenntnisse zu gewinnen, ist heute einer der wichtigsten Erfolgsfaktoren für Unternehmen. Eine gut durchdachte...
Zukunft der BI: 5 spannende Business Intelligence Trends für 2024
Die Bedeutung von Daten für den Unternehmenserfolg wächst stetig, und die Fähigkeit, diese effektiv zu analysieren und einzusetzen, wird immer...
Gartner Prognose: KI-Software wird bis 2027 auf 297 Mrd. USD anwachsen
Gartner sagt voraus, dass die weltweiten Ausgaben für KI-Software von 124 Mrd. USD im Jahr 2022 auf 297 Mrd. USD im Jahr 2027 ansteigen werden und...
Wie Business Intelligence und KI mittelständische Unternehmen revolutionieren
Im Zeitalter der Digitalisierung sind Business Intelligence (BI) und Künstliche Intelligenz (KI) zentrale Säulen der strategischen...